Image2Poem
Image-to-Poem
此情此景,何不吟诗一首?Image-to-Poem帮你完成!
项目链接:
https://github.com/weiji-Feng/Image2Poem
9.28之前可能会忙于升学,本项目暂不更新。希望可以在10.31号之前完成这个项目的全部功能。
1. 项目介绍
图像生成古诗(Image to Poem),旨在为给定的图像自动生成符合图像内容的古诗句。
使用对比学习预训练的CLIP模型拥有良好的迁移应用和zero-shot能力,是打通图像-文本多模态的重要模型之一。 本项目使用CLIP模型生成古诗意象关键词向量和图像向量。
初始版本的生成方法为:搜集一个古诗词意象关键词数据集(close-set),然后通过text-encoder(图1.右) 生成对应的关键词向量。对给定的一张图像,同样通过Image-encoder即可得到图像向量。比较图像向量和每个关键词向量的余弦相似度,可以得到top-k个相关关键词。将关键词送入语言模型,自动生成一首诗。
这种提取关键词的操作将会大大损失图像的语义信息,进而影响语言模型的古诗生成。但由于图像-古诗对数据集非常匮乏,我们很难</u>像Dalle模型一样</u>,直接将CLIP模型Image-encoder的输出向量,通过一个MappingNet(在DALLE-2中就是prior模块)送入解码器(语言模型)。所以如果有更好的想法欢迎指点。
由于古诗的特殊性,本项目重头训练了一个用于生成古诗文的Language Model,尝试了T5 model(223M)和GPT2 model(118M),现公开该预训练模型以供大家娱乐。
以上模型均可通过调用 https://github.com/huggingface/transformers 的transformers导入。
2. 引用和致谢
在项目完成期间,我参考并使用了以下项目,这里表示感谢!
- 数据集来源:https://github.com/THUNLP-AIPoet/CCPM
- CLIP预训练模型来源: https://github.com/OFA-Sys/Chinese-CLIP
- GPT2预训练部分代码:https://github.com/Morizeyao/GPT2-Chinese
3. 使用说明和生成样例
安装依赖库
1 | pip3 install torch torchvision torchaudio |
如果希望尝试预训练语言模型, 建议安装torch+cudaxx.x的GPU版本。
快速体验古诗生成
1 | python img2poem.py --image_path ./datasets/images/feiliu.jpg --model_type T5 --model_path ./config/t5_config |
其中:
--image_path: 图片所在位置--model_type: 模型名称,目前可选用’T5’,’GPT2’--model_path: 模型所在文件夹
生成样例

1 | 飞鹤度湖山,青松半掩关。水林昼景凤,诸君自有闲。 |

1 | 青碧绕瑶池,碧峰回九关。晚风吹画船,映水长成芳。 |

1 | 清江起玉龙,时听瀑布声。飞曲满游子,一生天上流。 |
4. 一些解释
- 对于当前项目的评价
提取关键词进行古诗生成是一个损失信息的过程,尤其是将图像映射到关键词的操作,损失了图像原本的语义(例如只能识别人,而不知道人在做什么)。所以效果上来看仍然差强人意。
没有给模型一些关于韵律、题材、体裁等的设定,导致不够专业。
可不可以使用自己的古诗数据集尝试预训练?
可以,不过由于CCPM数据集是
.json文件格式,导入方式与.txt不同。所以在datasets.py文件里你需要重新写一下有关文件导入的部分。并且由于预训练方法多样,你也可以修改预训练时的一些策略。项目的预训练方法是什么?
首先对于GPT2模型,常规预训练方法就是自回归,本项目尝试了mask关键词的方法,例如:
[CLS]关键词:明月 故乡 [EOS] 举头望明月,低头思故乡[SEP]=>[CLS]关键词:明月 故乡 [EOS] 举头望[MASK][MASK],低头思[MASK][MASK][SEP]然后我额外对这些mask token的预测准确率进行了计算,加入了损失函数中。
对于T5模型,由于是encoder-decoder架构,我使用下列格式创建数据:
x =
[CLS]关键词:红豆 南国 发 愿君[EOS][SEP], y =[CLS]红豆生南国[EOS][SEP]x =
[CLS]关键词:红豆 南国 发 愿君[EOS]红豆生南国[EOS][SEP], y =[CLS]秋来发故枝[EOS][SEP]x =
[CLS]关键词:红豆 南国 发 愿君[EOS]红豆生南国[EOS]秋来发故枝[EOS][SEP], y =[CLS]愿君多采撷[EOS][SEP]x =
[CLS]关键词:红豆 南国 发 愿君[EOS]红豆生南国[EOS]秋来发故枝[EOS]愿君多采撷[EOS][SEP], y =[CLS]此物最相思[EOS][SEP]通过什么方式进行图像生成古诗?未来有什么进一步更新的方法?
现在的实现比较简单,就是先搜集一个闭环的关键词数据集(
keyword.txt),然后使用CLIP对图像和所有关键词进行编码,计算它们之间的相似度,取相似度最高的K个关键词,然后放置于语言模型进行生成。由于
图像-古诗对数据集非常匮乏,似乎暂时做不到删去这个闭环关键词数据集。未来如果有充足的数据集,我会使用CLIP-MappingNet-T5/GPT2的模型架构进行训练,例如下图的CLIPCap架构: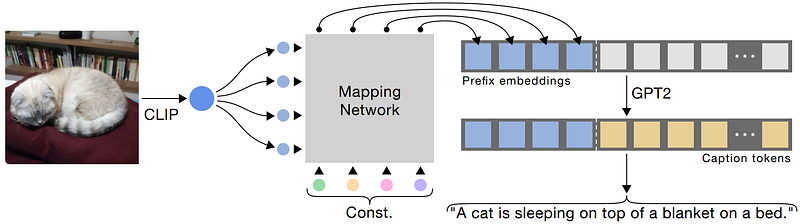
未来有古诗生成图像的想法,待进一步更新。现有的可以进行古诗生成图像的项目有:https://huggingface.co/IDEA-CCNL/Taiyi-Diffusion-532M-Nature-Chinese



