Contrastive Learning based Vision-Language Pre-Training
基于对比学习的多模态预训练方法
——以Vision-Language PTMs为例
前记:这篇文章是我在面试中科大毛震东老师组时写的一份报告,整理一下2023年之前基于对比学习的多模态预训练模型文献。算是给我的
Image-to-Poem项目做的一个综述性调查,给自己一个方向。
Abstract
1 | 随着大量图像-文本对数据集的涌现,使用对比学习进行多模态模型预训练的方法也愈发成熟。 |
1. Introduction
最近的工作证明,使用互联网中的大量图像-文本对进行多模态模型预训练可以显著提升模型的表征提取能力和泛化性能,但也对图像表征(Representation)和文本表征的融合提出了挑战。如何将图像表征与文本表征进行匹配是重要的问题。
基本地,这里将多模态模型预训练过程分为3个阶段:
- 将图像和文本分别编码为保留语义的表示向量(latent representations);
- 设计一个模型或结构,来模拟两种模式的交融;
- 设计有效的预训练任务来预训练Vision-Language Pre-Trained Model.
图像-文本对比学习(ITC)作为一种有效的预训练任务,欲将成对的图像-文本对的表示向量尽可能地拉近,而将不成对的负例样本对(negatives)的表示向量尽可能地远离。一般地,对比学习的损失函数(image-to-text为例)可表示为如下形式:
其中,$(W, V)$是图像-文本对数据集的一个样本,是关于$V$的负样本,$\textit{\pmb{h}}$是图像或文本的表征向量。在后续对多模态的各个预训练模型的调研中,可以发现上述对比学习思想和损失函数很少被改变;但是为了提升ITC任务的有效性,很多方法被引入,例如:正负样本对的定义、ITC任务的出现时机(如align before fusing)、Momentum Distillation等,这将在后续章节详细讨论。
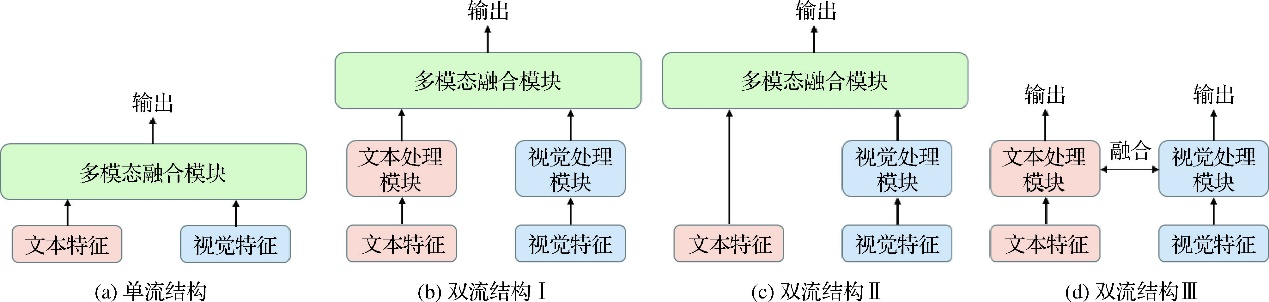
考虑到多模态模型结构具有多样性,需要对后续讨论的模型作一定的限制。根据主流分类,多模态模型分为单流(single-stream)和多流(dual-stream)两类,如图1所示。单流模型通常直接将图像编码向量和文本编码向量直接拼接,再接入融合编码器(通常是transformer结构)训练。显然,此类结构不适合引入ITC任务进行预训练,故将其剔除。
2 Approach
2.1 CLIP - Contrastive Language-Image Pre-training
我们首先介绍CLIP模型,是因为其是第一个使用对比学习而将zero-shot分类任务做到先进性能的。CLIP模型借用自然语言处理领域中使用自回归方式进行无监督训练的思想,意图用大量的文本监督信号训练视觉模型。
具体而言,CLIP模型的对比学习正负样本对定义比较简单:对于一个包含N个图像-文本对的batch数据,正样本为每张图像及其对应的文本(N个),而其他任意的图像-文本组合都作为负样本(N(N-1)个)。训练方法如图2所示。
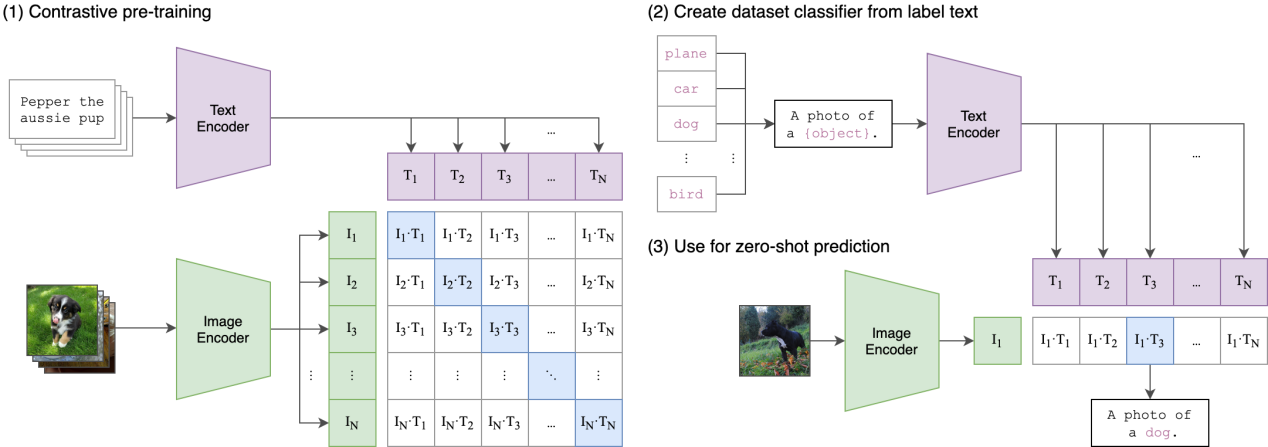
从对比学习算法角度,模型通过几下几步进行训练:
- 模态内编码:文本通过Text-Encoder编码为文本表示向量,图像通过Image-Encoder编码为图像表示向量。
- 模态间融合:即文本表示向量和图像表示向量的点积,计算相似度。
- 对比损失计算:这里使用CrossEntropy Loss作为损失。
从上述简洁的训练步骤,亦可看出在数据规模足够大的前提下,对比学习是非常有潜力的。除了性能上的优异,对比学习给大模型预训练还带来了以下几个优势:
- 训练效率的提升。以往工作表明,在ImageNet上训练一个大模型(
ResNeXt101-32x48d)需要大量训练资源,像在4亿图文数据的开放视觉识别任务上,效率更是非常重要。与图像生成对应文本的预训练任务相比,对比学习能够提升至少4倍的效率。 - Zero-shot能力的展现。对比学习通过拉近相关的图像和文本编码,从而使得每张图片总能找到最佳匹配的类别标签,并且不会像监督学习那样受到类别标签的限制。
尽管CLIP模型的训练方法使得其在分类任务、图文检索任务上有出色的表现,但由于模态间的融合有限(仅仅是相似度计算和对比学习),很难在QA或者生成任务上有比较好的性能。
2.2 ALBEF - ALign the image and text representation BEfore Fusing
ALBEF模型的研究动机是极其具有价值的,并且给基于对比学习的多模态预训练做了一个有效过渡,成为了一个新的范式。具体而言,该模型从模型和数据2个角度做了改进:
- 模型结构层面:指出利用目标检测器进行区域图像特征抽取的办法,由于文本embedding和图像embedding并未对齐而使得模态融合成为挑战;而利用巨大数据集进行对比学习的方法(如CLIP)也因融合不足而无法应用在更多任务上。
- 数据层面:web收集的图像-文本对含有大量噪声,直接进行对比学习可能会过拟合噪声样本。
图3展示了ALBEF模型的结构。和CLIP模型相似,该模型引入12层的ViT-B16结构作为图像编码器,并引入BERT结构作为文本编码器。不同的是,BERT被拆为了前六层的文本编码器和后六层的multimodal融合器,既体现了融合编码器的重要性,也体现了图像编码器更为重要的实践结论。ALBEF的预训练包含3个任务,因为篇幅限制,我们重点讨论ITC任务。
首先讨论ITC任务的执行时间:align before fusing。这使得单模态编码器提前学习到低维单模态表示,进而实现更容易的模态融合。
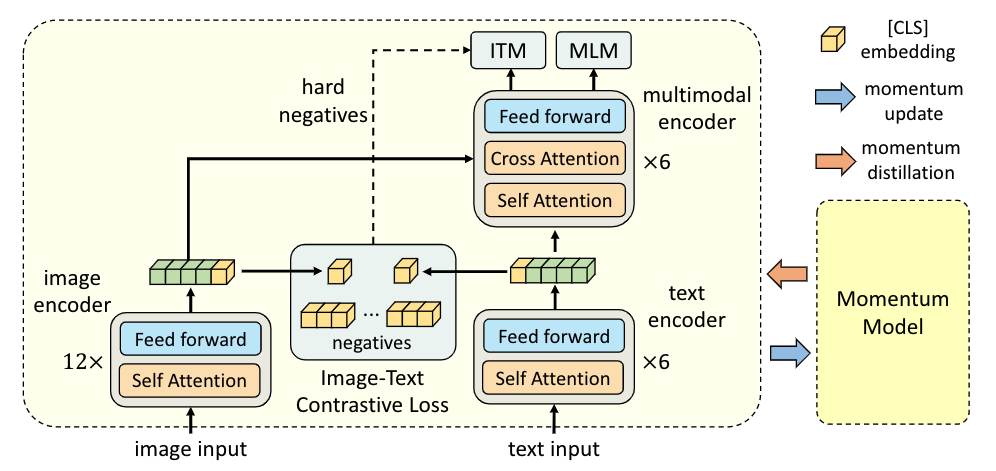
其次讨论ITC任务的正负样本对定义。借鉴MOCO论文的思想,作者将对比学习看作构建动态字典。以image-to-text角度为例,首先构建一个队列queue用以存放text数据(即key),然后每一个image数据(即query)都进行字典查找:query总与匹配的key相似(正样本对),而与其他key相异(负样本对)。在实际的ITC任务中,query是用image-Encoder编码的图像向量,而key则是用一个相同或相近的Encoder(被称为Momentum Model)编码的文本向量。最终的对比损失为:
最后我们讨论Momentum Distillation。用于预训练的图像-文本对通常是noisy的:正样本对很可能是弱相关的,而负样本对也可能相互匹配。那么简单地使用对比学习的one-hot label(正负2个类别)将会惩罚所有的负样本对,忽略那些更好的描述文本。因此引入soft label是必要的,具体地,利用Momentum Model生成图像-文本相似度(即soft label)作为伪标签,和ITC任务生成的图像-文本相似度计算KL散度,衡量两者的相似性。可以看出,动量蒸馏鼓励模型捕获那些稳定的语义信息表示,并最大化那些具有相似语义的图像和文本的互信息。加入Momentum Distillation(MoD)后,对比损失更新为:
2.3 BLIP – Bootstrapping Language-Image Pre-training
BLIP系列模型设计的初衷,是实现统一的视觉语言理解和生成预训练,以弥补现有模型(Encoder-Based & Encoder-Decoder)的不足。
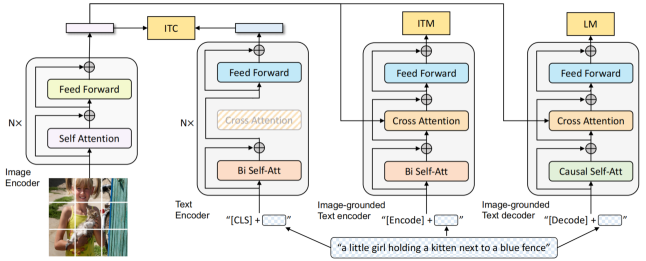
对于BLIP模型(图4左),它在ALBEF的基础上加入了权值共享,并将MLM任务替换为LM任务以加强模型生成的性能。在ITC任务上,其依旧应用了Momentum Model,以保证文本和视觉特征空间的对齐。此外,论文提出的CapFilt方法不仅可以提高数据集的质量,还可以增加数据集数量,大幅增强了预训练模型的性能,成为了多模态数据处理的新范式。
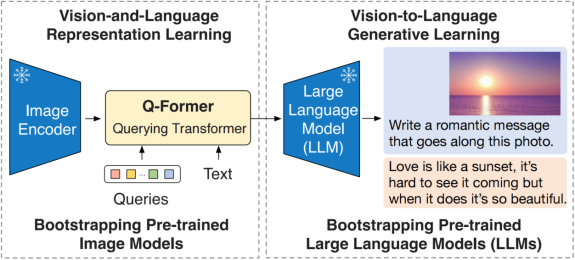
BLIP-2模型(图4右)期望使用图像和文本单模态里的先进的大规模预训练模型来提供高质量的单模态特征,并保证计算效率足够高。于是它们冻结了Image Encoder和LLM,通过两阶段的预训练步骤取得了先进结果:
- 使用轻量的模块Q-Former从image Encoder中捕捉包含丰富文本信息的视觉特征;
- 使用冻结的LLM进行语言生成任务。
有趣的是,Q-Former结构并不直接对图像特征和文本特征进行对比学习,而是定义了一组learned query(如图5所示),在和Image Encoder的编码向量进行cross-attention后,与文本向量进行对比学习。这被认为是在提取与文本信息高度对应的视觉表示。同时为防止信息泄露,文本信息和query经过了Uni-modal self-attention mask。
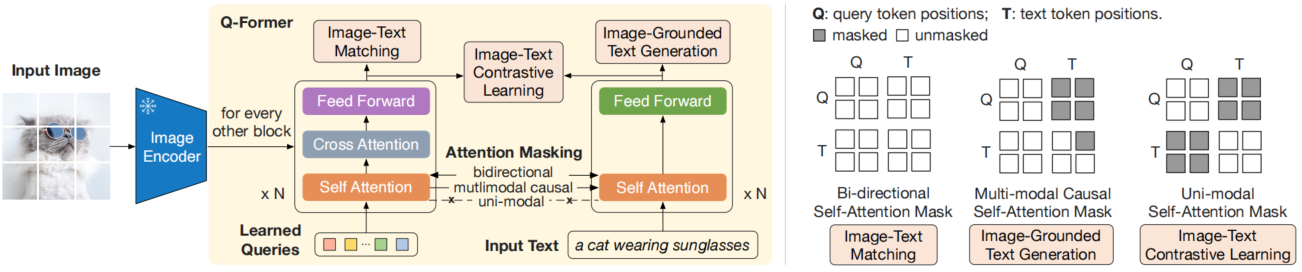
最后,BLIP2没有延续Momentum Distillation,这是因为冻结的Image Encoder无需反向传播(即Encoder无需变化),无需动量变化,而且节省了GPU的容量,可以容纳更多的样本。因此in-batch的负样本就已经足够。关于BLIP2中有趣细节因篇幅原因不再展示。
3 Our Work
基于对比学习的多模态预训练模型因为捕获了丰富的多模态表征,展现出了强大性能,使得Image captioning成为可能。我们尝试进行图像生成古诗,一种特殊的字幕生成任务。该项目(Image2Poem)已在近期开源至:https://github.com/weiji-Feng/Image2Poem。
如果你希望了解项目细节(可能性不大),你可以点击上面的github链接,也可以跳转到我的另一篇博客
<暗格>Image-to-Poem.
3.1 Pre-training Datasets
根据现有资源,我们搜集了109727首来自各时期的绝句,并给出每首古诗的关键词。我们将数据保存为.json格式,每个样本的形式如下所示:1
2
3
4
5
6
7{
"dynasty": "Tang",
"author": "王维",
"content": "清浅白沙滩|绿蒲尚堪把|家住水东西|浣纱明月下",
"title": "白石滩",
"keywords": "清浅 明月 东西 白沙"
}
我们筛选了数据集中的关键词,组成了6000余个核心关键词集合。
3.2 Model Architecture
由于图像-古诗对数据的匮乏,我们的初代版本使用两阶段的生成方式。
如图6所示,我们通过两个步骤进行推理:
- CLIP编码:我们首先将关键词集合通过text encoder进行编码,保存以供多次使用。其次,将感兴趣的图像通过image encoder编码,获得图像embedding。我们比较图像embedding和所有关键词embedding的相似度,选择top-k个关键词作为古诗生成的prefix。
- Decoder生成古诗:利用BERT tokenizer对prefix进行分词,进而通过预训练的Decoder模型生成古诗。
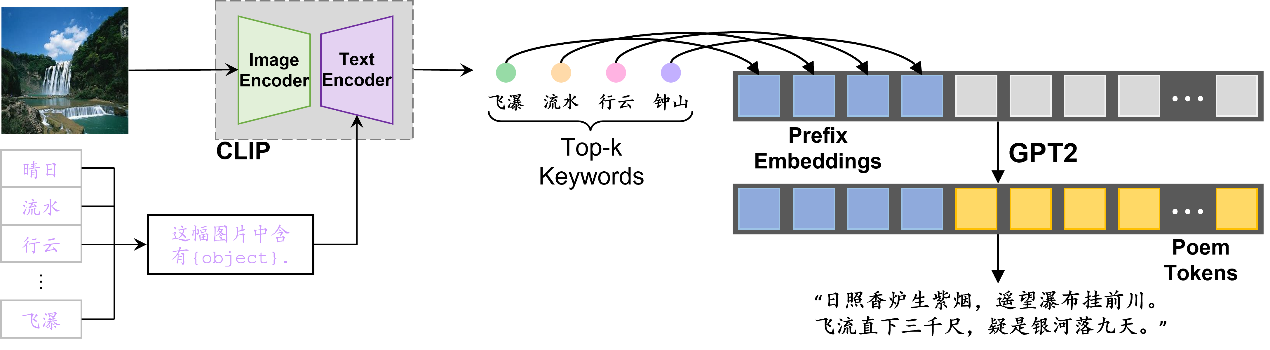
我们预训练了2个版本的生成式模型:GPT2(Decoder型)和T5(Encoder-Decoder型)。我们将keywords作为模型的输入,期望模型生成符合要求的古诗。训练期间,我们加入一定的MLM策略:对诗中出现在关键词中的字,我们采用15%的概率进行mask掩码,期望让模型学会在古诗生成中包含关键词。
3.3 Model Improvement
要做模型的改进,我们认为核心是收集高质量图像-古诗对数据集。我们准备进行如下两阶段的数据集获取:
- 利用预训练的BLIP2/Chinese-CLIP进行图文检索,获取古诗的对应相关图像;
- 对于匹配度不高的图像-古诗对数据,我们考虑Stable Diffusion生成的方式。
拥有数据后,我们使用图7的结构进行端到端的预训练方式。具体而言:我们冻结预训练的CLIP模型参数和GPT2模型参数,只训练transformer-based的Mapping Network。借鉴BLIP2的思想,我们期望Mapping Network可以对齐图像编码空间和GPT2的文本空间。与BLIP2类似,我们设计了一个固定的learned queries,与CLIP图像编码器的输出进行融合(使用concatenate或者cross-attention),再将输出作为prefix embedding提供给GPT2模型。
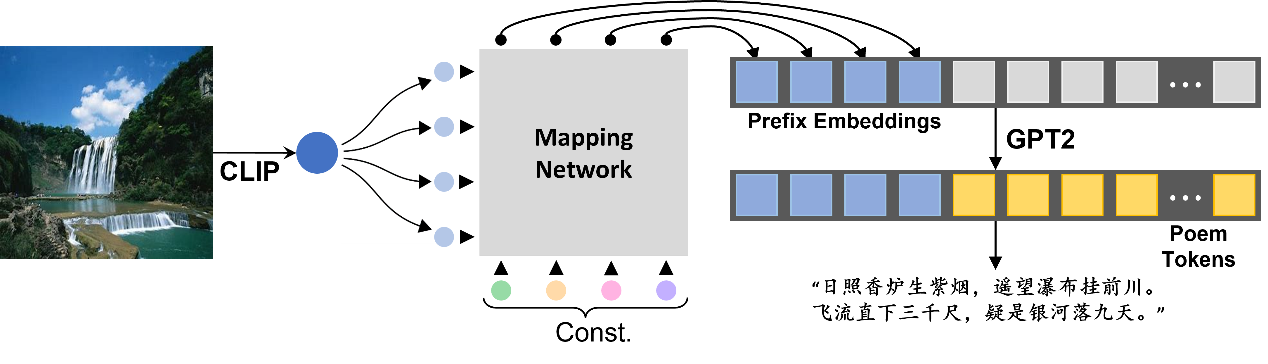
由于还在进行图像-古诗数据的检索,还没能对改进的结构进行测试,但我们相信这个改进是有意义的。



