Instance-wise Hard Negative Example Generation for Contrastive Learning in Unpaired Image-to-Image Translation
论文阅读 - Instance-wise Hard Negative Example Generation for Contrastive Learning in Unpaired Image-to-Image Translation
论文有一个重要的结论:在基于对比学习的图像翻译任务中,负样本(negative examples)的质量和难度是非常重要的。和之前的方法CUT相比,本文提出的方法能够产生足够challenge的负样本,从而使得对比学习可以捕捉那些具有细粒度的可区分特征。
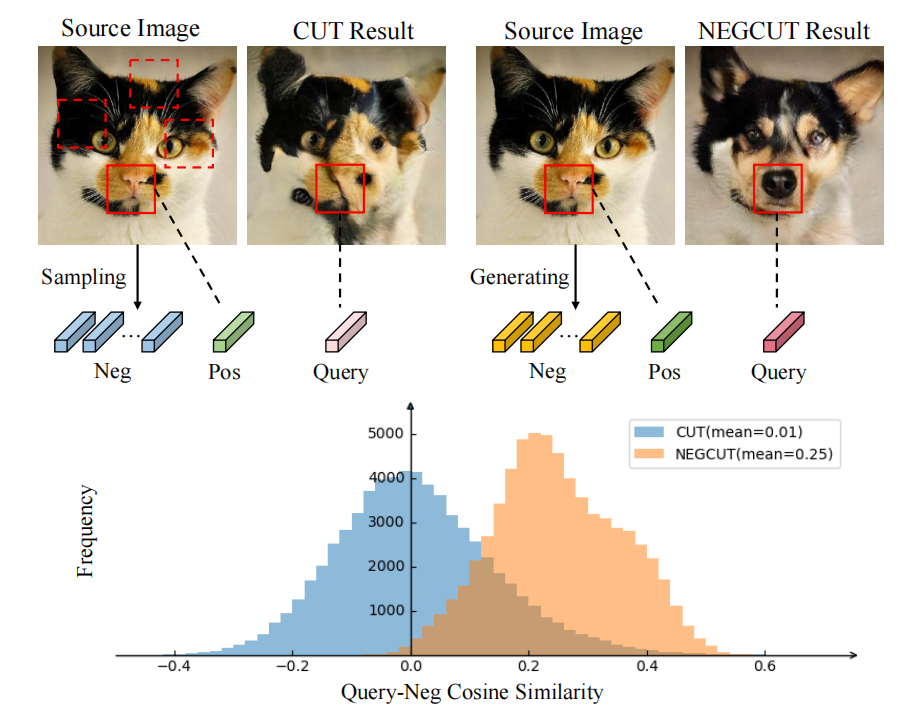
我们可以从图1中看到,与本文提出的方法相比,CUT方法产生的负例与query相似度不高,这也限制了CUT方法的效果:
由于论文是对CUT方法的一个改进,故我们首先引入CUT方法,来探索其使用对比学习的动机;再详细谈谈论文的方法NEGCUT是如何改进负样本的生成方法的;最后,我们沿着负样本的质量和难度这一线索,尝试阐述自己的一些想法。
1. 论文介绍
1.1 CUT - Contrastive Learning for Unpaired Image-to-Image Translation
图像翻译任务的核心工作就是在跨域生成图像时分离content和appearance,保留原图中的内容,将外观改变为目标domain的样式。举例而言,图像中对应zebra forehead的patch在经过generator生成后,应当是horse forehead而不是其他的部位。
cycle-consistency为了在非配对图像翻译任务中保证翻译(生成)前后图像信息的一致性,假设图像翻译任务的两个domain满足双射关系,这个严格的限制使其在相当一部分任务上(尤其是两个domain信息量差距较大时)效果不佳。同时,其需要一对generator来生成不同域的图像,对于只需要one-sided translation的任务而言无疑是增加了工作量。
而CUT则是基于互信息最大化思想,利用对比学习思想去捕捉对应的输入输出图像之间的共性部分,从而鼓励保留那些content信息。同时,作者注意到图像在每个patch上也是满足content不变的性质。于是作者采用patchwise的InfoNCE Loss来完成这个任务。
结构上,论文需要一个generator进行domain adaptation,并且需要一个encoder捕获content信息并进行对比学习,框架图2所示:
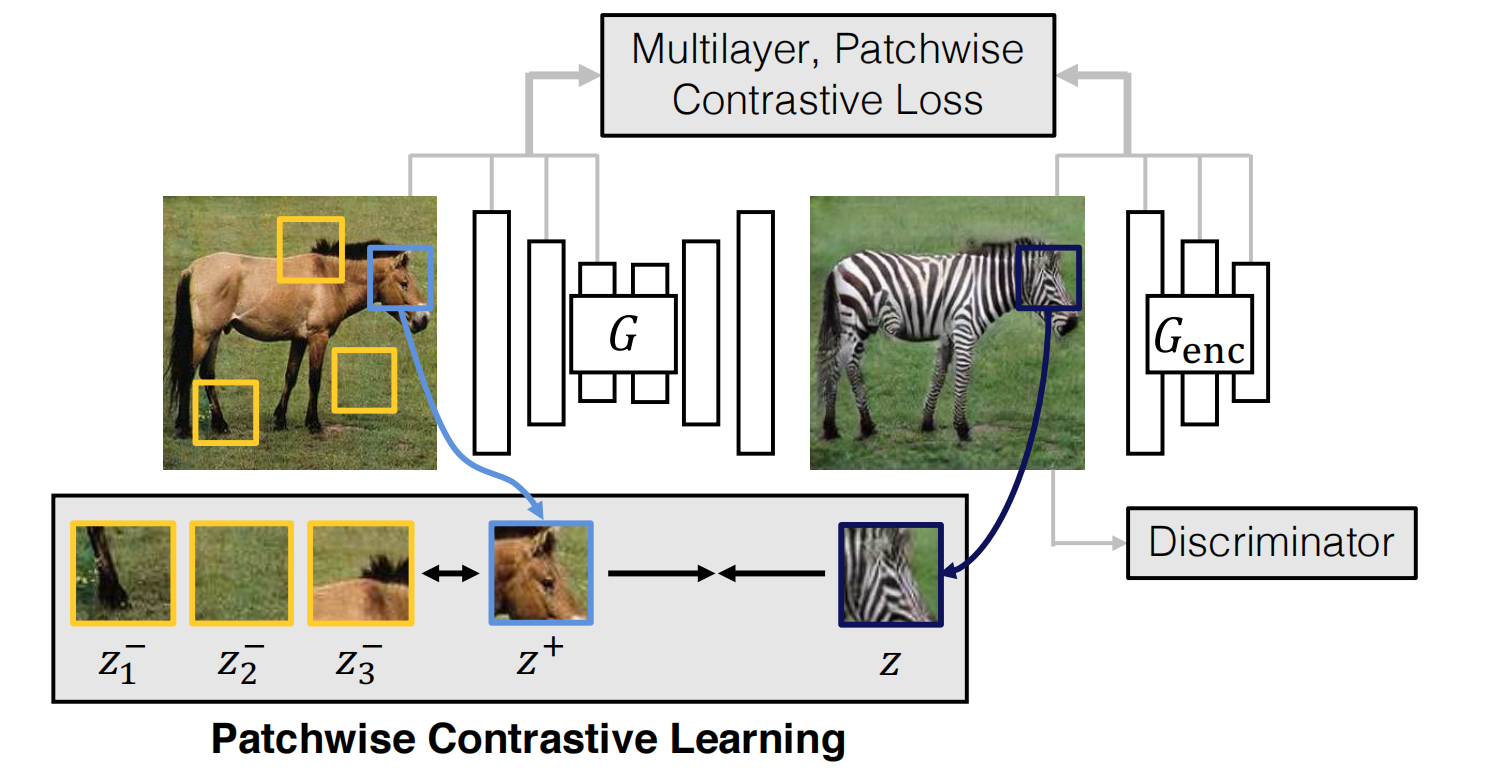
于是他自然需要以下2个损失函数部分:
- Adversarial loss:鼓励生成的图像和目标domain有一致的“风格”;
- Mutual information maximization:鼓励输入和输出的对应位置有更紧密的联系,或是互信息。
1.1.1 对比损失
由于对比损失是GAN-based模型所必须的损失,我们不再详细探讨它,直接给出公式如下:
1.1.2 互信息最大化
如果要使用对比学习来实现互信息的最大化,应当使query和positive两个信号关联起来,而数据集中的其他信息都被定义为negative。如果我们令 $\text{query}=v,\ \text{positive}=v^+,\ \text{negative}=v^-$,我们当然希望 $v$ 和 $v^+$ 的距离/相似度最高,和negative的相似度越低,故我们可以定义一个InfoNCE Loss:
上式实际上是通过交叉熵损失进行计算的。
现在,我们的重点转移到如何选择对比学习的对象(即image or patch)、如何获取负样本。
论文提到,在图像翻译任务中,不仅生成前后的图像共享content,对应的patch也是共享content的,他们采取了一个patch-based、multilayer的对比学习策略。
对于每一层,模型设计了一个encoder(来自generator)+MLP的编码结构,如下图所示:
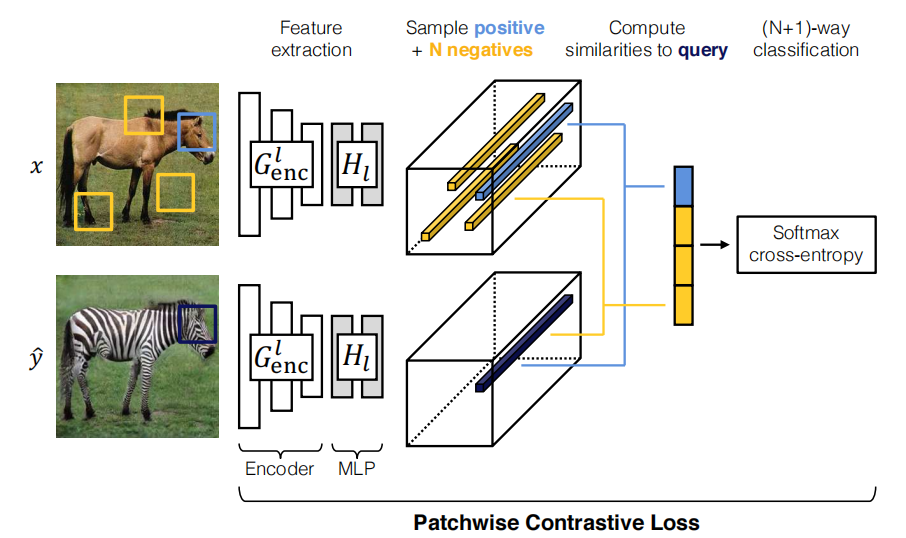
一个patch在第$l$层上的编码向量表示为
设这一层的特征有 $S_l$ 个position,则其第 $s$ 个position的向量应该为 $z_l^s$ 。同理我们也给目标domain类似的定义(将 $z$ 转换为 $\hat{z}$ ),那么式(2)可以更新为:
其中我们将目标domain的patch设为query,将input的对应patch设为positive,图片中其他位置的patch设为negative。我们只分享within图像的负样本,不在赘述external的情况。
最后,为了避免生成图像产生额外不必要的变化并且让generator更focus on那些content的信息,论文引入了一个identity loss(与CycleGAN中提到的类似) $\mathscr{L}_{\text{PatchNCE}}(G,H,Y)$,总的训练损失函数定义为:
1.2 NEGCUT
论文的模型结构和CUT方法中的类似,都是通过一个generator生成目标domain的图像,并通过generator的encoder去获取特征向量,进行多层的对比学习。论文的模型结构如下图所示: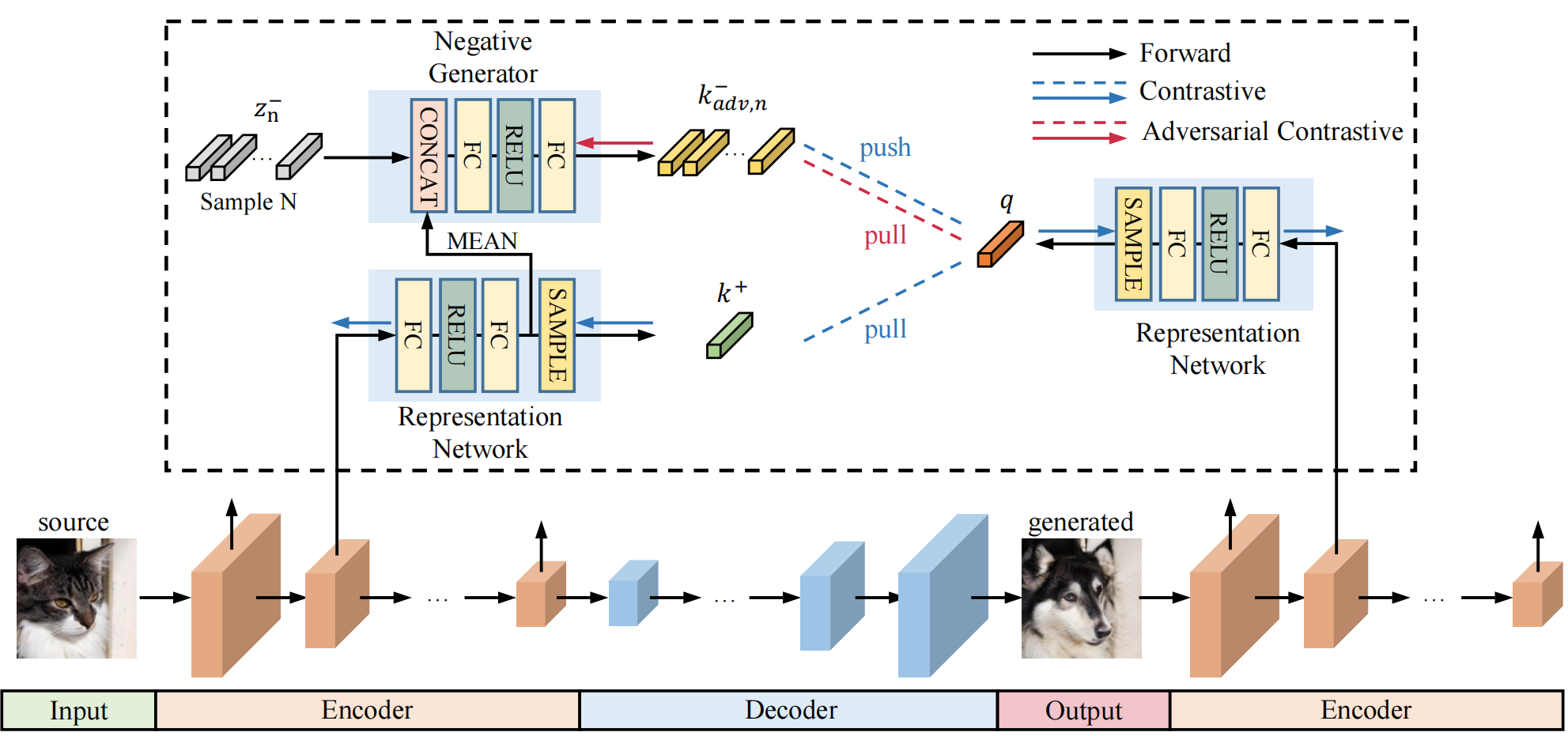
下面,我们着重理解论文制造Hard Negative Examples的方法。对于从encoder中的某一层 $l$ 获得的图像特征,论文使用一个由2-layer MLP组成的Representation Network $H^i(\cdot)$来进一步提取高维表示。
与CUT类似,论文对空间维数中的S个位置进行随机抽样,并以归一化向量作为query和positive进行对比学习,公式如下:
其中 $F_i$ 是encoder第i层获取的特征,$Y$ 是目标域,$X$ 是源域(source domain)。下标 $s$ 表示采样到的样本位置。
现在,我们需要第i层的negative样本特征。由于图像内的patch不够challenge,论文采用生成的办法去创造负样本。于是论文为第 $i$ 层设计了一个独立的negative generator $N^i$,它将接受Representation Network中的spatially-average特征 $\overline{H^i(F_i^{\pmb{\text{X}}})}$,和一个提供多样性的噪声 $z_n$,输出一个生成的负样本:
其中我们可以为每一个正样本采样多个 $z_n\sim N(0,1)$ 从而生成多个负样本。
为了使negative generator能够生成足够有挑战的负样本,论文选择将encoder(包含representation network)和negative generator进行对抗学习,损失如下所示:
其中,negative generator通过产生challenge的负样本来影响式(7)的分母使其最大化。而encoder和Representation Network则尽可能让query和正样本接近而使损失最小化,从而达到均衡。
由于论文采用了多层的对比学习,所以最终的对比学习损失如下:
为了避免模式崩溃mode collapse,论文引入一个diversity loss,迫使生成的负样本具有多样性:
当然,由于论文也是GAN-based,需要一个对抗损失来保证生成器生成的图片足够真实,符合目标域的特性:
论文还将损失准确分配给了不同的模型,如:
仔细看图4,其实可以看到损失的反向传播过程:例如contrastive loss(应该是公式(7)中要最小化的部分)将从representation network开始传播,而adversarial contrastive loss则仅用以训练负例生成器等。
1.3 Idea Mining
鉴于NEGCUT做了一个很好的改进,使得我认为对比学习在unpaired图像翻译任务中还能发挥更强烈的作用。下面,我来阐述一下我通过阅读论文做的一些思考:
为什么公式6会选择将空间的均值作为负生成器的输入:初看文章,我就有这个疑惑。我完全可以选择patch附近的空间做均值,这应该会比使用所有position的均值更具challenge。但与
CUT对比后,我发现这个想法应该源于CUT模型将图像内patch作为负样例的思想:做了均值后的向量总会包含整张图片的信息,添加噪声 $z$ 后理论上可以与图片中的任意一个patch近似。如图5所示,可以发现negative generator总是可以生成与当前patch较为相似的负例向量。所以,该方法其实可以获取很多与当前patch接近,但不局限于图像内的负样例。最后,使用附近patch的均值可能会产生太过困难的负样本,阻碍了正样本和query的学习。
图5. Negative examples visualization 如何保证生成的负样本的分布是真实的:从消融实验里,可以看到负例确实能够检索到与正样本相近的patch,但没有对其分布做进一步探索,例如:它真的属于source domain吗?这似乎并没有确切的证明他们。我想,设计一个判别器来判别生成的负例是否服从真实负样本的分布可能是一个解决方法。
另外,根据这个问题,我依然想通过CUT的方法——即图像内部的patch进行解决。CUT方法中将所有 $S-s$ positions的向量引入PatchNCE Loss中,给予了它们相同的权重,即:
那如果我们可以分配给hard negative examples一个更高的权重,或许又会有更好的效果。
- 对比学习如何保证translate前后content的一致性:准确来说,对比学习通过拉近
query图像patch和positive图像patch从而保留其内容相近。但是patch级的局部对比学习或许会影响图像级的content信息,例如source domain两个接近的patch反而在目标域不再接近。因此我认为引入patch之间的距离或相似度来监督图像translation的质量也是有一定意义的。



