科研经历简介
个人科研经历总结
1. FacTool: Factuality Detection in Generative AI
论文所在地址:https://ethanc111.github.io/factool_website/
这个应该是我大学生涯里真正开始参与的第一个科研项目,方向是对生成式AI的事实性检测(factuality/hallucinations)。像ChatGPT这样的LLMs可以生成各种类型的response(QA/code generation/math reasoning/scientific review),但是它们却经常会编造事实,给人们带来困扰。本工作主要针对以下4种常见场景设计了检测方案,并将该工具集成到LLMs中进行实时的检测:
knowledge-based QA: Factool detects factual errors in knowledge-based QA.code generation: Factool detects execution errors in code generation.mathematical reasoning: Factool detects calculation errors in mathematical reasoning.scientific literature review: Factool detects hallucinated scientific literatures.
下面我以自己主要参与的scientific literature review模块为例,阐述一下FacTool的原理。
1.1 如何实现事实性检测
论文中提到实现该工具需要五个step:
- claim extraction
- query generation
- tool querying
- evidence collection
- agreement verification
本质上其实只需2个prompt和特定的附加工具:
prompt 1:提取claim
即从一段scientific literature review中提取出引用到的论文(claim),每篇提取出来的论文必须包含(paper title, year, author)三个属性。我们只需要一个prompt即可实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19scientific:
system: |-
You are a brilliant assistant.
user: |-
You are given a piece of text that mentions some scientfic literature. Your task is to accurately find all papers mentioned in the text and identify the title, author(s), and publication year for each paper.
The response should be a list of dictionaries, with each dictionary having keys "paper_title", "paper_author(s)", and "paper_pub_year", which correspond to the title of the paper, the authors of the paper, and the publication year of the paper.
Please note that only papers that include both title, author, and year of publication in the text are eligible. Papers that lack a title or author or publication date are not allowed to appear in the response.
The following is the given text
[text]: {input}
You should only respond in format as described below (i.e., a list of dictionaries). Remember not to repeat papers in each response. Papers that lack a title or author or publication date are not allowed to appear in the response. If the paper title is empty, please ignore the paper. DO NOT RESPOND WITH ANYTHING ELSE. DO NOT RESPONSE TO DUPLICATE CONTENT.
[response format]:
[
{{
"paper_title": "Title of the paper(you can write "' '" if there are no titles).",
"paper_author(s)": "Author(s) of the paper(you can write "' '" if there are no authors).",
"paper_pub_year": "Year of the paper published(you can write "' '" if there are no years)."
}},
...
]
下面给出一个样例,看看ChatGPT通过该prompt生成的内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20{
"input_review": "The current state-of-the-art deep learning algorithms for natural language processing include transformer-based models such as BERT (Devlin et al., 2018), GPT-2 (Radford et al., 2019), and T5 (Raffel et al., 2019). These models have achieved state-of-the-art performance on various NLP tasks such as question answering, language translation, and text generation.",
"output_claims": [
{
"paper_title": "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding",
"paper_author(s)": "Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova",
"paper_pub_year": "2018"
},
{
"paper_title": "Language Models are Unsupervised Multitask Learners",
"paper_author(s)": "Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever",
"paper_pub_year": "2019"
},
{
"paper_title": "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer",
"paper_author(s)": "Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu",
"paper_pub_year": "2019"
}
]
}
tool 1:querying - 使用工具采集证据
这一步比较简单,我们可以通过Google Scholar实现证据采集。
- input:文章题目
- output:google scholar页面第一个检索结果的题目、年份、作者信息。
这里直接给出实现代码:1
2
3
4
5
6
7
8
9
10class google_scholar():
def __init__(self):
pass
def run(self, query):
"""query: the extracted title of the paper"""
results = scholarly.search_pubs(query)
paper_info = next(results)
paper_info_subset = {key: paper_info['bib'][key] for key in ['title', 'author', 'pub_year']}
return paper_info_subset
我们只需要把上一个步骤中提取出的paper信息(仅需要title)传入google scholar,通过比较output的搜索结果和提取出的信息之间的差异,就能判断真实性。
prompt 2:对方法的评估
由于我们需要测试和评估FactTool的性能,所以必须拥有测试数据集。下面是2段prompt,分别要求GPT完成情景生成(即要求生成一个scientific question)和情景问题回答(完全无错、包含一个错误并提取出这个错误)。通过该方式最终可以获得一个包含多个领域的review数据集。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23scientific:
prompt_generation:
system: |-
You are a brilliant assistant.
user: |-
Can you give me 20 prompts that ask to generate content that includes citing relevant scientific papers? The prompts should cover {computer science, medicine, law, business, physics}. The prompt should specify that When citing relevant papers, please include the name of the papers, the author(s) of the papers, and the publication year.
response_generation:
system: |-
You are a brilliant assistant.
user: |-
Answer the given scientific question with exactly one reference error (i.e., contain a hallucinated scientific paper) so that my students can debug that error.
Your answer concise and in full sentence(s).
The response must be a dictionary with keys "answer_without_error", "answer_with_one_hallucinated_scientific_paper", and "error", which correspond to the correct answer without error, the answer with one reference error, and the error itself.
The following is the given question
[question]: {input}
The format of papers introduced in "answer_without_error" should be: a study by [author name](year of publication) titled '[paper title]'. You must only respond in format as described below. DO NOT RESPONSE TO PAPERS WHOSE AUTHOR NAMES CONTAIN THE FOLLOWING WORDS: "Jane", "John", "Doe", "Smith". DO NOT RETURN ANYTHING ELSE. ADDING ANY EXTRA NOTES OR COMMENTS THAT DON'T FOLLOW THE RESPONSE FORMAT IS ALSO PROHIBITED.
[response format]:
{{
"answer_without_error": "Answer without error. Ensure that the answer is highly factual. REMEMBER RESPONSE MUST INCLUDES THE TITLE OF THE PAPER ENCLOSED IN QUOTATION MARKS. Answer in full sentence(s).",
"answer_with_one_hallucinated_scientific_paper": "Answer with one reference error (i.e., contains a hallucinated scientific paper). Answer in full sentence(s). Make sure the hallucinated scientfic paper is convincing and not randomly generated.",
"error": "The error itself."
}}
总结
针对一个领域的事实性检测基本都按照上述过程完成。这个方法虽然可以高精确度地完成事实性检测,但由于一般性略有不足,导致目前只能在4个领域展开检测。最近第一作者还在提高检测的泛化能力。
2. LLM for Math reasoning
例如GPT-4这样的大语言模型已经依靠其出色的语义理解能力和强大的上下文记忆,在很多NLP任务中展示出了强大的能力。但由于LLM的预训练使用的是大量互联网数据,并没能在数学相关任务中展现出亮眼的表现,其数学推理能力较差。我总结了一下其中的几个原因:
- 推理思路混乱:对于复杂的数学推理任务,其找不到推理出发点或步骤跳跃;
- 运算能力较差:经常出现数学运算错误(乘除开方等),导致错误随推理深入不断放大;
- 数据格式混乱:现有的数学相关数据(如GSM8K,MATH,MultiArith等)格式不一,而LLM对于不同格式数据体现出的理解能力有很多不同。
我们工作针对这些问题,采用了以下方法:
- Chain-of-thought:由于思维链的使用通常能显著提高LLM的逻辑推理能力,我们在微调过程中沿用了这个方法,使用的每个数据集都有step-by-step的求解过程;
- Supervised fine-tuning:由于LLM在数学知识储备上有所不足,所以我们通过使用sft方法,直接改进模型在数学知识上的不足;
- Adding out-domain datasets:为了增强LLM在数学运算、常识逻辑上的能力,我们引入多个相关数据集,期望这些领域的知识可以间接提升其在数学上的推理能力;
- reformat:将所有数据标注成相同的格式,有助于模型的统一理解。
值得强调的是,多篇论文指出模型的能力与训练数据的数据量呈对数级的正相关,所以我们在加入以上4种方法的基础上还同时引入多种数据增强方法,使数据不仅数量众多,并且有效。下面,我们详细介绍一下本工作的内容。
1. In-domain dataset
即领域内相关数据集。它的组成如下:
train set of the benchmarks
即领域内数据集的训练集,最常见的就是GSM8K和MATH数据集,使用这些数据的训练集可以使得LLM在这些数据集的评估中表现出色。
data augmentation by GPT-4
例如GSM8K的训练集仅有7473条数据,数据量较小,我们还需要通过GPT-4去造新的题目,我们可采用两种方法:
参数化法:
1
2"base": "In a school, there are 120 students. The number of boys is 4 times the number of girls. How many boys and girls are there in the school?"
"param": "In a school, there are $x$ students. The number of boys is $y$ times the number of girls. How many boys and girls are there in the school?"通过对上述参数化题目中的和赋值,我们就能获得更多的增强数据。
情景制造法:
即通过few-shot,通过从原数据集中sample出一些题目,给GPT-4提供样例,让其生成新的、同类型的题目。1
2
3
4
5
6
7"prompt": {
"1": "Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did she earn?",
"2": "Randy has 60 mango trees on his farm. He also has 5 less than half as many coconut trees as mango trees. How many trees does Randy have in all on his farm?",
"3": "Joy can read 8 pages of a book in 20 minutes. How many hours will it take her to read 120 pages?"
}
=> GPT-4
"response": "In a school, there are 120 students. The number of boys is 4 times the number of girls. How many boys and girls are there in the school?"
reject sampling
我们知道,针对同一道题可能会有多种解题思路,如果在微调中只给出一个正确答案,难免会限制LLM的“思维”。
reject sampling方法使用sft微调完(即只是用训练集初步微调)的模型,让其回答K次,收集其中答案正确且推理步骤不同的数据组成新的增强数据,继续微调。这样做的好处有:
- 生成的数据是模型自身生成的,使得数据更贴近模型的输出概率分布;
- 生成多个推理路径,有助于提升模型的推理思维。
1
2
3
4
5
6"question": "Julie is reading a 120-page book. Yesterday, she was able to read 12 pages and today, she read twice as many pages as yesterday. If she wants to read half of the remaining pages tomorrow, how many pages should she read?"
"answer": "Maila read 12 x 2 = <<12*2=24>>24 pages today.\nSo she was able to read a total of 12 + 24 = <<12+24=36>>36 pages since yesterday.\nThere are 120 - 36 = <<120-36=84>>84 pages left to be read.\nSince she wants to read half of the remaining pages tomorrow, then she should read 84/2 = <<84/2=42>>42 pages.\n#### 42"
=> sampled by sfted model itself.
"new_answer_1": "The number of pages that Julie read today is 12 x 2 = <<12*2=24>>24.\nSo, the total number of pages that she read yesterday and today is 12 + 24 = <<12+24=36>>36.\nThus, the total number of remaining pages is 120 - 36 = <<120-36=84>>84.\nSince she wants to read half of the remaining pages tomorrow, then she should read 84/2 = <<84/2=42>>42 pages.\n#### 42"
"new_answer_2": "Since today is the 3rd day, then Julie read a total of 12 + 24 = <<12+24=36>>36 pages for the first two days.\nJulie's total number of pages left to read is 120 - 36 = <<120-36=84>>84 pages.\nSo, she needs to read 84/2 = <<84/2=42>>42 pages tomorrow to read half of the remaining pages.\n#### 42"
Evol-Instruct
这个方法来源于Wizard-Math论文,通过对推理数据的复杂度(难度)和涉猎广度进行修改而让数据涉及更广泛的情况。其主要策略有:
- Downward evolution:降低题目难度。包括将复杂的题分解为简单的题、生成一个其他主题的简单的新问题;
- Upward evolution:升高题目难度。包括增加限制条件、增加推理步骤等。
reformat
即把推理过程的格式修改为一种容易让LLM理解和应用的格式。例如:在第一步复述和总结题目的要求;给每个step前加一个序号,如“1.”表示第一步;在所有步骤结束后提示“[[Final solution]]”表示“综上所述”。1
2
3
4
5"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?"
"base_answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n#### 72"
=> reformat
"reformat_answer": "1. The problem states that Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. We need to find out how many clips Natalia sold altogether in April and May.\n2. By problem, Natalia sold 48 clips in April.\n3. By problem, Natalia sold half as many clips in May as she did in April. Since she sold 48 clips in April, she sold 48/2 = <<48/2=24>> = 24 clips in May.\n4. To find out how many clips Natalia sold altogether in April and May, we need to add the number of clips sold in April and May together. By steps 2 and 3, Natalia sold 48 clips in April + 24 clips in May = <<48+24=72>> = 72 clips altogether in April and May.\n5. [Final solution] Thus, Natalia sold 72 clips altogether in April and May. #### 72"
reformat过程可以通过few-shot GPT-4即可实现。
2. Out-domain dataset
这一部分就是通过借助与推理能力间接相关的数据集,例如:多位数的运算题、与推理有关的其他数据集等。下面简单地列举几个使用的数据:
arithmetic算术题
1
2
3
4
5{
"question": "63405533102770 + 119761662",
"target": "63405652864432",
"answer": "63405533102770 + 119761662 = 63405652864432"
}IMO竞赛题
1
2
3
4
5{
"idx": 96, "year": 2018, "competition": "IMO shortlist", "tag": ["algebra", "combinatorics"],
"question": "Let $\\mathbb{Q}_{>0}$ denote the set of all positive rational numbers. Determine all functions $f:\\mathbb{Q}_{>0}\\to \\mathbb{Q}_{>0}$ satisfying $$f(x^2f(y)^2)=f(x)^2f(y)$$for all $x,y\\in\\mathbb{Q}_{>0}$",
"answer": "$f(x)=1, \\forall x\\in \\mathbb{Q^+}$$P(x,y) \\rightarrow f(x^{2}f(y)^2)=f(x)^{2}f(y) $$P(1,x) \\rightarrow f(f(x)^2)=f(1)^{2}f(x)...(A)$$P(\\displaystyle \\frac{x}{f(x^2)},x^2) \\rightarrow f(x^2)=f(\\frac{x}{f(x^2)})^{2}f(x^2)$ $\\Rightarrow f(\\displaystyle \\frac{x}{f(x^2)})=1$$\\exists c\\in \\mathbb{Q^+}$ such that $f(c)=1$$P(x,c) \\rightarrow f(x^2)=f(x)^2$$P(x,y^2) \\rightarrow f(xf(y)^2)^2=f(x)^{2}f(y)^{2}$ $\\Rightarrow f(xf(y)^2)=f(x)f(y) ... (1)$In (1) let $x=1$ and we obtain $f(f(y)^2)=f(1)f(y)...(B)$Combining (A) and (B) yields $f(1)=1$So $f(f(x)^2)= f(f(x))^2= f(x)$ $\\Rightarrow f^k(x)=\\sqrt[k]{f(x)}$ where $k$ is a power of $2$.Suppose that for some $a\\in \\mathbb{Q^+}$ such that $f(a)\\neq 1$ let $f(a)=\\displaystyle \\frac{m}{n}$ such that $\\gcd(m,n)=1$Let $k$ be a power of $2$ with $V_{p}(m)<k \\wedge V_{p}(n)<k$ for all primes $p$.$f^k(a)=\\sqrt[k]{f(a)}$ so $\\sqrt[k]{f(a)} \\in \\mathbb{Q^+}$Let $\\sqrt[k]{\\displaystyle\\frac{m}{n}}=\\displaystyle\\frac{x}{y}$ for some $x,y \\in \\mathbb{N}$ with $\\gcd(x,y)=1$$my^k=nx^k$ if $p \\mid m \\Rightarrow p \\mid x$$V_{p}(my^k)=V_{p}(nx^k)$ Since $\\gcd(x,y)=1$ $V_{p}(y)=0$$V_{p}(my^k)=V_{p}(m)=V_{p}(x^k)=k \\cdot V_{p}(x) \\geq k$ this is clearly a contradiction and thus there doesn't exist any positive rational number $a$ with $f(a)\\neq 1$."
}khan etc.
3. Reward Model
我们知道,由于LLM生成回答实际上是对概率模型进行采样,所以如果我们将temperature参数变大,我们就可以获得自由度更高的回复,这样我们多次采样,可能会获得不同的生成结果。
怎样的生成结果是好的呢?下面是常见的几种评判方法:
- greedy decode:
temperature=0.0,采样1次,得到唯一的解码结果。该方法可以获得固定的回答。 - majority voting:
temperature=0.7,采样K次进行投票,票选次数最高的结果(出现次数最高的解)被认为是最终答案,是greedy decode的一般情况; - reward model,建立一个新的评价模型,让其去选择最佳的回答。

而reward model被认为是效果更好的一种评估策略。所以如何有效训练一个reward model是人们所关心的。Open-AI提出一个Process-supervised Reward Models,通过给每一个步骤进行打分,并整合所有步骤的分数为该回答的总得分。这种方法能细粒度地检测每个步骤是否出现问题,能监控推理出错的时机。
该方法如何训练?需要人工标注如下数据。
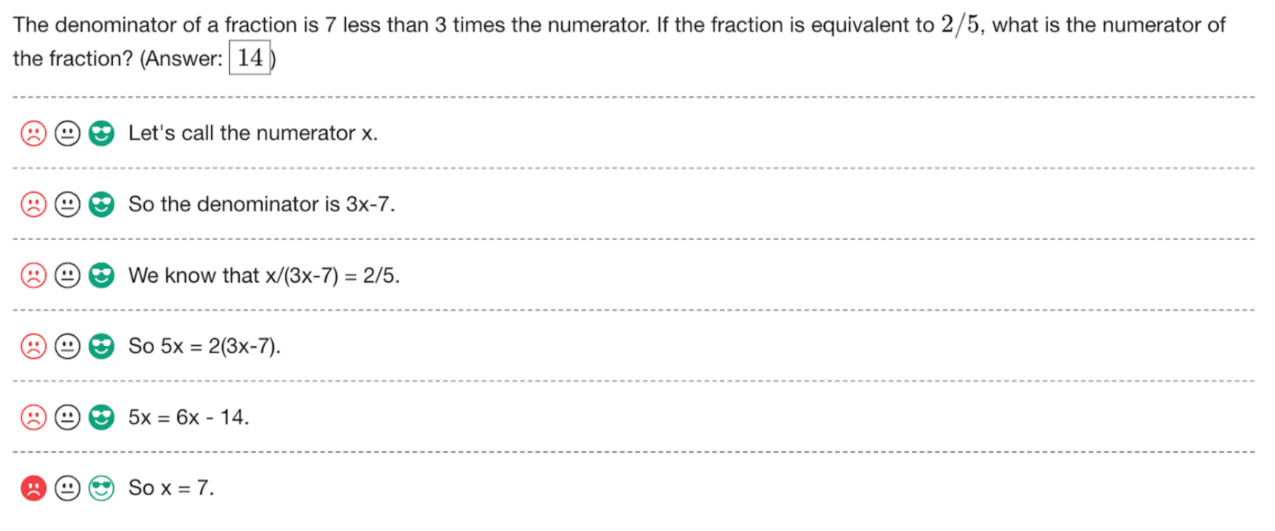
3. Image2Poem
这是我本科阶段独立开展的第一个项目。图像生成古诗(Image to Poem),旨在为给定的图像自动生成符合图像内容的古诗句。
使用对比学习预训练的CLIP模型拥有良好的迁移应用和zero-shot能力,是打通图像-文本多模态的重要模型之一。 本项目使用CLIP模型生成古诗意象关键词向量和图像向量。
初始版本的生成方法为:搜集一个古诗词意象关键词数据集(close-set),然后通过text-encoder(图1.右) 生成对应的关键词向量。对给定的一张图像,同样通过Image-encoder即可得到图像向量。比较图像向量和每个关键词向量的余弦相似度,可以得到top-k个相关关键词。将关键词送入语言模型,自动生成一首诗。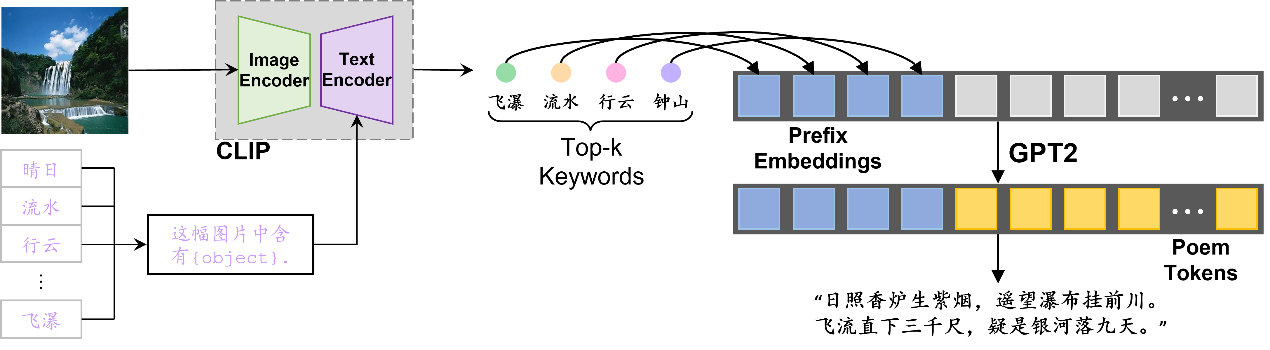
不过我们的理想是实现一阶段端到端的生成,如下图所示:
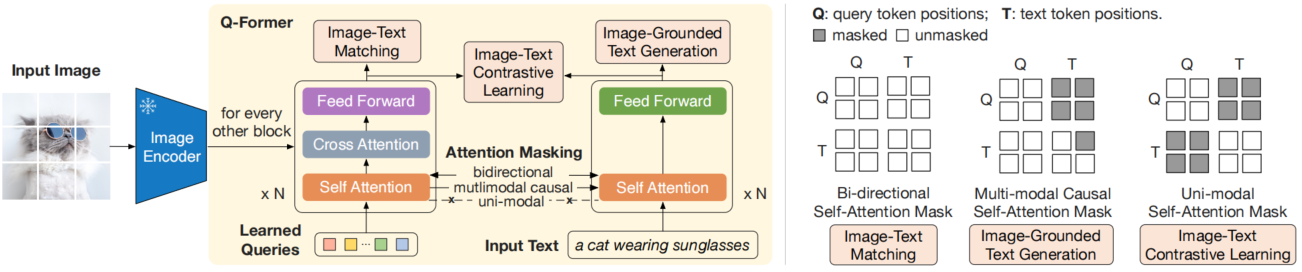
我的初步构思是借鉴BLIP2的Q-Former框架,如下图所示